Proceedings of 15th Annual Meeting of the Cognitive Science Society, (pp. 463-468). Hillsdale, NJ: Erlbaum.
© Cognitive Science Society
A computer model of chess memory1
Fernand Gobet
Department of Psychology
Carnegie Mellon University
Pittsburgh, PA 15213
fg23@andrew.cmu.edu
Abstract
Chess research provides rich data for testing computational models of human memory. This paper presents a model which shares several common concepts with an earlier attempt (Simon & Gilmartin, 1973), but features several new attributes: dynamic short-term memory, recursive chunking, more sophisticated perceptual mechanisms and use of a retrieval structure (Chase & Ericsson, 1982). Simulations of data from three experiments are presented: 1) differential recall of random and game positions; 2) recall of several boards presented in short succession; 3) recall of positions modified by mirror image reflection about various axes. The model fits the data reasonably well, although some empirical phenomena are not captured by it. At a theoretical level, the conceptualization of the internal representation and its relation with the retrieval structure needs further refinement.
Introduction
Since the seminal works of de Groot (1965) and Chase and Simon (1973a,b), chess research has provided a large amount of psychological data, with a special focus on chess players' memory. The standard experimental paradigm in chess research consists in presenting a chess position for a short amount of time (generally 5 seconds), and then asking subjects to reconstruct it. The most common independent variables are presentation time, subjects' skill, and degree of meaningfulness of the position. Even though general models of chess expertise abound (for example, Holding, 1985), almost no detailed models of chess memory have been proposed, the exception being MAPP, the model developed by Chase and Simon (1973b) and implemented by Simon and Gilmartin (1973).
MAPP simulates the behavior of Class A chess players (good amateurs) in the recall task by first recognizing chunks on the board through a discrimination net, and then storing pointers to these chunks in a limited-size, static, short-term memory (STM). It captures some important features of the empirical data, including the differential recall of random and meaningful positions and the kind of patterns that are likely to be recognized. However, some limitations have been indicated by Simon and Gilmartin. For example, MAPP was unable to explain the high number of chunks (more than the 7±2 predicted by the theory) replaced when a position is recalled by a chess expert. In addition, it fails to offer an explanation for some new data including the lack of effect of interfering material on memory performance (Charness, 1976; Frey & Adesman, 1976).
This paper proposes a new model of chess memory that is partly inspired by MAPP. The main additions are 1) the presence of dynamical updating processes in STM; 2) a more deeply elaborated discrimination net, which includes recursive chunking; 3) more sophisticated perceptual mechanisms; 4) the implementation of the concept of retrieval structure (Chase & Ericsson, 1982), which is a long-term memory (LTM) template into which the new information can be encoded rapidly. In the following section, I shall give an overview of the model, dubbed CHREST, for CHunk Hierarchy and REtrieval STructures. I shall then present in more detail the components and the processes of the model. Finally, a sample of the simulation runs with the model will be described, and CHREST's adequacy will be discussed.
Overview of the model
CHREST consists of a blending of ideas proposed in earlier computer models of different aspects of chess cognition (MATER, Baylor & Simon, 1966; PERCEIVER, Barenfeld & Simon, 1969; MAPP, Gilmartin & Simon, 1973), with adjunction or modification of some concepts motivated by recent empirical and theoretical research. The model is implemented in LISP.
The model consists of the following structures:
• a visual space;
• a short term memory, limited to about seven items;
• an associative long term memory, accessed by a discrimination net. Knowledge in LTM is encoded as schemas and productions;
• a retrieval structure, that permits a rapid encoding into LTM; it consists of an hypothesis, which is the pattern containing the largest quantity of information 2 up to that point, and of an internal representation, which is a schematic representation of the chess board. The assumption is that, with strong players, the hypothesis gives access to information located in semantic LTM 3, such as the initial moves the position is likely to come from, the possible plans and moves in the position, and so on.
The theoretically important mechanisms are the following:
• mechanisms allowing the traversal of the discrimination net;
• mechanisms for growing the discrimination net (learning);
• mechanisms directing the attention and the eye movements, and therefore allowing the perception of stimuli on a external board 4;
• mechanisms for updating the hypothesis;
• mechanisms for adding information to STM and to the internal representation.
During the reconstruction phase, some rough inference processes are used: the model does not propose placing a piece that has already been reconstructed; it also avoids exceeding the legal number of occurrences of a given piece by erasing a piece of the same type that has already been placed.
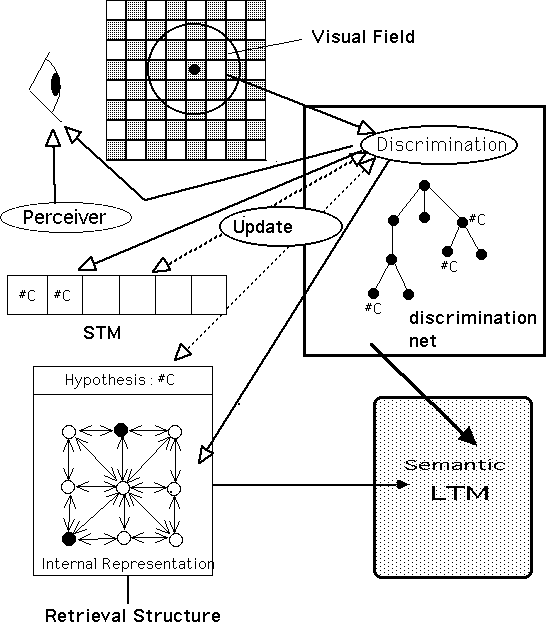
Figure 1 depicts these structures and mechanisms, which I will illustrate by describing the simulation of the recall of one position. Once a square has been fixated (the initial fixation point is one of the 4 central squares), the model examines the information in the visual space by sorting it through the discrimination net. If a pattern is recognized, a symbol pointing to it is stored in STM. In addition, the square (with possibly a piece on it) is stored in the internal representation. The model considers, then, the present hypothesis (in the absence of a hypothesis, the first pattern perceived plays this role), and tries to discriminate further by using the information contained in the STM and the internal representation. If a new hypothesis is found, the old one is placed into STM. The model then selects a new square to fixate, and the cycle starts again. At the end of the presentation of the position, the model reconstructs it by placing, in order, the pieces of the hypothesis, of the STM and of the internal representation.
Figure 1: Schematic representation of CHREST.
Description of the model
Discrimination net
CHREST uses a discrimination net close to the one used by EPAM, a theory that has been successfully applied to a variety of phenomena in learning and perception (Feigenbaum & Simon, 1984; Richman & Simon, 1989). The net, which is made of a set of nodes 5 and links, allows the assignment of a stimulus to its representation in memory, by performing a sequence of tests on the characteristics of the object. Before being fed to the net, the stimulus is first analyzed as a set of attribute-values pairs and/or sub-objects. Two different types of learning occur with both EPAM and CHREST. When an object is recognized as being different from the chunk the net sorted to, a new test is added. This test applies to a characteristic of the object that allows the net to discriminate it from the object with which it was confounded. This mechanism is called discrimination. If the object is recognized as being compatible with the chunk the net sorted to, new characteristics are added to the image of that node. The image is the internal informational representation of an external object. This mechanism is called familiarization. These two types of learning operate in a discrete way.
The net used in CHREST keeps some of the assumptions of EPAM, such as the discrete character of learning, the permanency of the net (nodes and links are not erasable), the avoidance of any backtracking in the traversing of the net, and the presence of two learning mechanisms, discrimination and familiarization. In comparison with the EPAM net used by Gilmartin and Simon (1973) in chess simulations, new features have been added: n-arity (MAPP had a binary tree), hierarchical and recursive organization of information, and redundancy in the encoding of the information. The latter feature occurs in the following way. When two symbols pointing to a LTM node are stored into STM, the images of these nodes are compared (the order of the elements is not considered); if the test gives a positive result, a link —called a redundant link— is created between these two nodes. Afterwards, such links may be used during the net traversing processes. One of the consequences of the presence of such links is that any node may be accessed from any arbitrary number of nodes.
Internal representation and retrieval structure
The concept of retrieval structure has been proposed by Chase and Ericsson (1982) in their study of the extraordinary digit memory of one of their subjects (see also Staszewski, this volume). In CHREST, the retrieval structure is construed as a schema composed of two attributes: the hypothesis, which is the chunk (reached after discrimination through the net) that possesses the largest amount of information, and the internal representation of the board. This representation is close to the one proposed by Newell and Prasad (1963), and is encoded as a list structure. Such a structure may be visualized as a network of nodes and links. The nodes themselves possess attribute-value schemas.
In the internal representation of CHREST, squares of the board are connected by the chess relations between them. A (potentially disputable) assumption is that the internal representation is the same for players of different skills, given that a minimal level is present. An alternative, though bound with difficulties due to the lack of empirical data on chess learning, would have been to simulate the construction of the internal representation.
It is supposed that information may be encoded rapidly in the retrieval structure, but that the retrieval structure itself may not be duplicated. This proposition is supported by the phenomenon of progressive deepening (de Groot, 1965); if the duplication of the retrieval structure was easy, players could create as many such structures as positions searched and would need only one visit per position. But de Groot precisely showed the necessity for human players to reinvestigate the same position several times during the analysis.
STM and updating mechanisms
As stated above, STM is implemented as a limited capacity structure, of about seven symbols. Once this capacity is attained, the arrival of a new element will cause the oldest one to be discarded. Symbols may point to a node in LTM or to the retrieval structure.
A criticism of many STM models, including the model incorporated in Simon and Gilmartin's (1973) simulation, is the lack of connection between the STM elements. It is intuitively more plausible that the cognitive system uses new information to process the old information more deeply and to obtain in this way a better representation of the world. This is similar to the idea proposed by Carpenter and Just (1989), that subjects, during a reading task, interpret information as soon as possible. CHREST tries to update constantly its hypothesis of the position, by using new information. In CHREST, the following cycle is performed: 1) information from the visual field is incorporated to STM and to the internal representation; 2) the hypothesis is updated with the chunks being held in STM and in the internal representation. When either the hypothesis is updated or a pattern containing more pieces is found in the visual space, the old hypothesis is placed into STM, and the updated hypothesis or the new pattern takes its place.
Visual field and eye movements
In the model, the visual field is defined as the 25 squares (or less, when the focused square is on the side of the board) centered on the square presently focused. This estimate, based on empirical data provided by de Groot (1980), is somewhat arbitrary as the visual field may vary as a function of the physical size of the board.
The attention control and eye movement monitoring mechanisms are, in order of importance: 1) LTM mechanisms; when initiating a new fixation, the model tries to find a descendant of the last node found in the discrimination net and focuses, if possible, on its square; 2) defense and attack noticing strategies (cf. PERCEIVER, Barenfeld and Simon, 1969); 3) global strategies; they aim to gather information on key parts of the board, such as center, king's position and so on. For a simulation of eye movements and a discussion of their (qualitative) fit, see Gobet (1993).
Results of simulations
Learning phase
In the learning phase, the model investigates each position for 20 fixations (this parameter has been set arbitrarily). Each fixation augments the content of the current pattern. Pattern construction is terminated in one of three ways: 1) when the model focuses again on a piece already belonging to the pattern; 2) when some global strategy applies; or 3) when the 20 fixations are terminated. Once the construction of a pattern is finished, the model starts LTM discrimination. In order to increase the probability of forming redundant chunks, the STM capacity was set to 20 items during the learning phase.
2843 positions, taken from Hort and Jansa (1980) and from a personal database, were used during the learning phase. The Hort and Jansa set, which was studied first, contains 230 unrelated positions; the latter set contains entire games, providing a high level of redundancy between the positions. After the learning phase, the model had 3646 nodes in memory. Interestingly, the progression of the number of redundant nodes is very slow: 4 after 100 positions, 10 after 1000 positions, 14 after 2000 positions and 20 after having learned the totality of the material. If the model is (partly) correct, this would be an indication that the creation of redundant and multiply indexed knowledge occurs at a relatively advanced stage of expertise.
Recall of random vs. game positions
It is a classical result in cognitive psychology that experts in a domain (in our case, chess), achieve better results than novices in a memory task with short presentation when the material is domain meaningful, but that this difference vanishes when the material is domain meaningless, such as a random assignment of pieces on the chess board (Chase & Simon, 1973a). I have tested whether the model shows this differential recall of random and game positions. During the learning phase, a recall test was performed after each group of 10 positions. This test consisted in 2 game positions and 2 random positions (of course, no learning was done on these test positions). The average of the last 100 tests is 10.66 pieces (sd = 1.08) for the game positions and 7.77 pieces (sd = .65) for the random positions. The difference is statistically highly significant [t(99) = 21.924, p< .0001, one-tailed]. It should be noted that the recall of random positions is greater than the recall found with human subjects (about 4 pieces).
Recall of several positions
As stated above, Charness (1976) has shown that memory for chess positions was resistant to interfering tasks, even with chess related tasks (in his study, name the pieces or find the best move in another position). Frey and Adesman (1976) reached the same conclusion. In their experiment subjects were presented 2 positions, and were asked to recall the first or the second of these positions. Extending this technique, Gobet and Simon (1992) have presented subjects with up to 5 positions at a rate of 5 sec. each, where recall was asked on all positions. This section discusses the CHREST simulation of that study.
Three snapshots were taken in the course of learning: after the study of 230 positions (N230; total number of nodes = 630), of 1538 positions (N1538; n=2175) and 2843 positions (N2843; n=3646). The number of fixations 6 during the presentation of the position was set to 20, and STM capacity to 7. Finally, during the presentation, the model was allowed to familiarize the image of the hypothesis with a chunk stored in STM. Sets of 1 up to 5 positions were presented to the model, which was required to recall as much as possible of all positions. Each net was tested on 4 sets of positions by experimental condition.
The upper panel of Figure 2 (next page) depicts the results obtained by CHREST, and the lower panel the human data (Gobet & Simon, 1992, experiment #1b). As the 3 nets show similar results (a state of affairs that will be taken up in the discussion section), they are pooled in the following analyses. The Number of positions has a significant effect [F(4,44)=131.04, p<.001]; the linear component is significant as well [F(1,11)=47.93, p<.001]. As the model accounts for 97.4% of the Class A players' results in Gobet and Simon's experiment #1b and 77.5% in their experiment #3, the fit may be judged as reasonably good. A noticeable difference is that the model is better than class A human subjects with the recall of 4 and 5 positions.
Mirror image reflections of chess positions: effect on recall
It has been shown that the recall of chess positions is impaired when they are modified by mirror images about various axes (Gobet, 1993, Gobet & Simon. The effect is especially strong for mirror images about vertical and central axes.
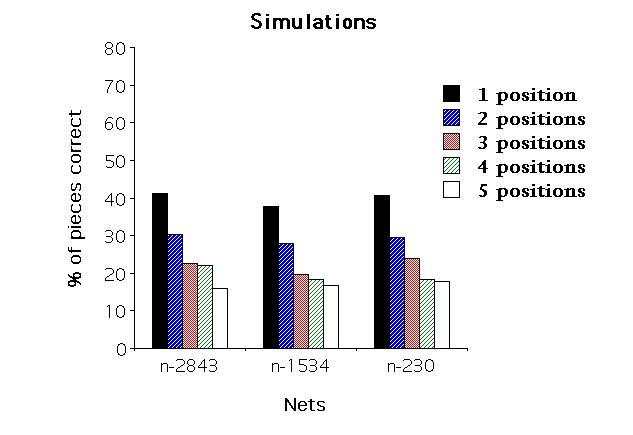
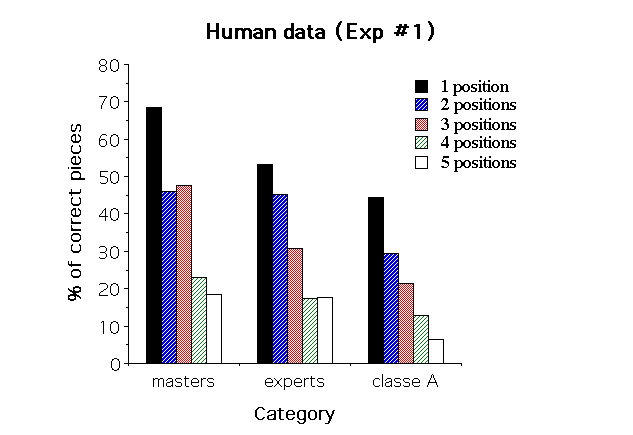
Figure 2: Recall of several positions (Upper panel: simulations; lower panel: human data).
Two simulations were performed. In the first one, the model had access to the information in the internal representation during recall (with-IR). In the second one, this information was not accessible (without-IR). In both cases, the model performed 20 fixations before starting the reconstruction, and STM capacity was set to 7. The nets were the same as the ones described in the preceding section. 17 positions were used for each experimental condition. As there was no difference due to the number of positions learned, the trials of the 3 nets have been pooled in the statistical analysis. Figure 3 illustrates the results: The upper panel of the Figure refers to the model using the internal representation during recall, the middle panel to the model without the internal representation, and the lower panel to the results with humans (Exp. #1a in Gobet & Simon, 1992). No effect is found for the first case (with-IR) [F(3,33)=1.59, ns]. The effect reaches significance in the second case (without-IR) [F(3,33)=2.868, p=.051; F(1,11)=7.34, p=.02 when normal & horizontal conditions are pooled against vertical & central]. The results of the second simulation account for 89.2% of class A players in Exp. #2 and of 93.7% in Exp. #1a
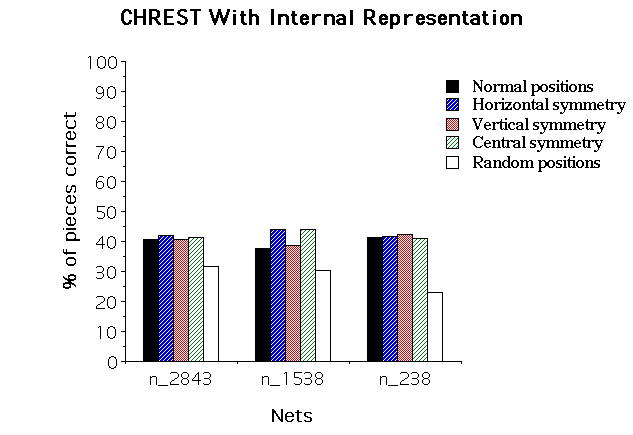
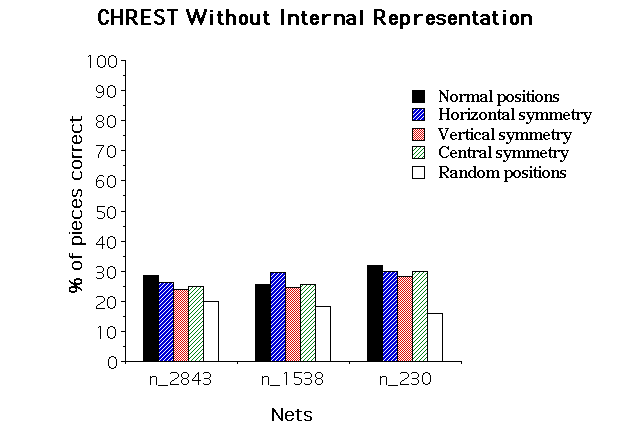
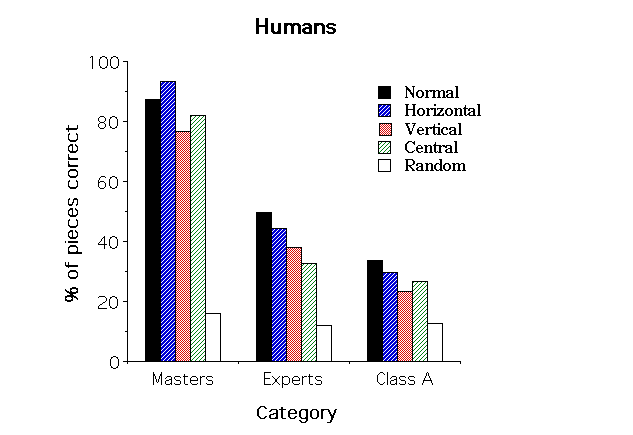
Figure 3: Effect of Mirror Image Reflection on Recall. Upper panel: CHREST, with information held in the retrieval structure used during recall; middle panel: CHREST, with information held in the retrieval structure not used during recall; lower panel: human data.
At the analysis of these results, it seems plausible to conclude that an important part of the effect was eliminated, in the first simulation, by the role played by the internal representation. The arbitrariness of this representation was already stressed above. This section suggests another weakness: the internal representation as conceptualized gives a uniform weight to the different regions of the board, when human players seem to give more importance to locations like the center and the King's side.
Discussion
Overall, the simulations may be credited with a satisfactory fit with the data. However, several problems remain. First, the model is able to recall random positions better than humans (7.7 pieces vs. about 4 pieces). It is not clear whether this difference is due to emotive factors (human subjects show very strong negative affects when confronted to random positions) or is the consequence of basic memory processes. Second, the inadequacy of the retrieval structure as implemented in CHREST has been established by the simulation of positions modified by mirror image reflections. A possible improvement is to restrict the retrieval structure to a few slots, say one for the center, one for the King's side, and so on. Such a partition definitely possesses a psychological justification (see for example the protocols of de Groot, 1965). Third, as the reader may have noticed, there is not much performance improvement between the 3 nets used in the simulations, so that comparisons had to be limited to Class A players. If CHREST is to be considered as a general theory of chess memory, it should be able to simulate the results of experts and masters. Currently, work is done to let CHREST learn the 50,000 chunks required, if we believe Simon and Gilmartin (1973), to reach the level of expertise. Fourth, the model lacks inference abilities, whereas it is not uncommon for human players to "guess" the location of certain pieces, especially at the end of the reconstruction. Finally, the strategies used by chess players to modulate their memory may have been underestimated in the model.
To conclude, a better fit to the data may be obtained without changing the fundamental conception of the model, but by tuning up some of its components. Special attention should be given to the role of the internal representation in the retrieval structure, and to its development as expertise grows.
References
Baylor, G. W., & Simon, H. A. (1966). A chess mating combinations program. Proceedings of the 1966 Spring Joint Computer Conference, Boston, 28, 431-447.
Carpenter, P. A. & Just, M. A. (1989). The role of working memory in language comprehension. In D. Klahr & K. Kotovski (Eds.), Complex Information processing, the impact of Herbert A. Simon. Hillsdale, NJ: Erlbaum.
Charness, N. (1976). Memory for chess positions: Resistance to interference. Journal of Experimental Psychology: Human Learning and Memory, 2, 641-653.
Chase, W. G., & Ericsson, K. A. (1982). Skill and working memory. In G. H. Bower (Ed.), The psychology of learning and motivation (Vol. 16). New York: Academic Press.
Chase, W. G., & Simon, H. A. (1973a). Perception in Chess. Cognitive Psychology, 4, 55-81.
Chase, W. G., & Simon, H. A. (1973b). The mind's eye in chess. In W. G. Chase (Ed.) Visual information processing. New York: Academic Press.
de Groot, A. D. (1965). Thought and Choice in Chess. The Hague: Mouton.
de Groot, A. D. (1980). Perception and memory in chess. Unpublished manuscript.
Feigenbaum, E. A., & Simon, H. A. (1984). EPAM-like models of recognition and learning. Cognitive Science, 8, 305-336.
Frey, P. W., & Adesman, P. (1976). Recall memory for visually presented chess positions. Memory and Cognition, 4, 541-547.
Gobet, F. & Simon, H. A. (1992). Memory for Chess Positions: Effect of Mirror Image Reflection and Recall of Several Boards. Complex Information Working Paper #501, Department of Psychology, Carnegie Mellon University.
Gobet, F. (1993). Les mémoires d'un joueur d'échecs. Doctoral Thesis, University of Fribourg. Fribourg: Presses Universitaires.
Holding, D. H. (1985). The psychology of chess skill. Hillsdale, NJ: Lawrence Erlbaum.
Hort, V. & Jansa, V. (1980). The Best Move. New York: R.H.M. Press.
Newell, A., & Prasad, N. S. (1963). IPL-V chess position program. Unpublished working paper. Carnegie Institute of Technology.
Richman, H. B., & Simon, H. A. (1989). Context effects in letter perception: Comparison of two theories. Psychological Review, 3, 417-432.
Simon, H. A., & Barenfeld, M. (1969). Information processing analysis of perceptual processes in problem solving. Psychological Review, 76, 473-483.
Simon, H. A., & Gilmartin, K. J. (1973). A simulation of memory for chess positions. Cognitive Psychology, 5, 29-46.
Staszewski, J. (this volume). A Theory of Skilled Memory.
Acknowledgments
I am grateful to Herbert Simon and Howard Richman for insightful discussions and comments on this paper. Thanks also to Paul Reber for providing me with his chess database, and to Jim Staszewski, Shmuel Ur and Peter Jansen for valuable comments on a first draft of this paper.
Footnotes
1
This research was funded by grant no. 8210-30606 from the Swiss National Funds of Scientific Research to the author and grant no. DBS-912-1027 from the National Science Foundation to Dr. H. Simon. Return to main text at pointer to footnote 1
2
In the simulations to be discussed, information is defined as the number of pieces contained in the chunk. Return to main text at pointer to footnote 2
3
This part of the model has not been implemented yet. Return to main text at pointer to footnote 3
4
In the simulations, the external chess board was encoded as a 8 x 8 matrix of characters. Return to main text at pointer to footnote 4
5
I will use the terms "chunk" and "node" interchangeably. Return to main text at pointer to footnote 5
6
De Groot's (1980) data show that about 20 fixations are performed in a 5 sec. exposition. Return to main text at pointer to footnote 6